
Multimodal output opens up new potentialities
Having true multimodal output opens up fascinating new potentialities in chatbots. As an example, Gemini 2.0 Flash can play interactive graphical video video games or generate tales with fixed illustrations, sustaining character and setting continuity all by a lot of footage. It’s from good, nevertheless character consistency is a model new performance in AI assistants. We tried it out and it was pretty wild—significantly when it generated a view {a photograph} we provided from one different angle.

Making a multi-image story with Gemini 2.0 Flash, half 1.
Google / Benj Edwards
Making a multi-image story with Gemini 2.0 Flash, half 1.
Google / Benj Edwards
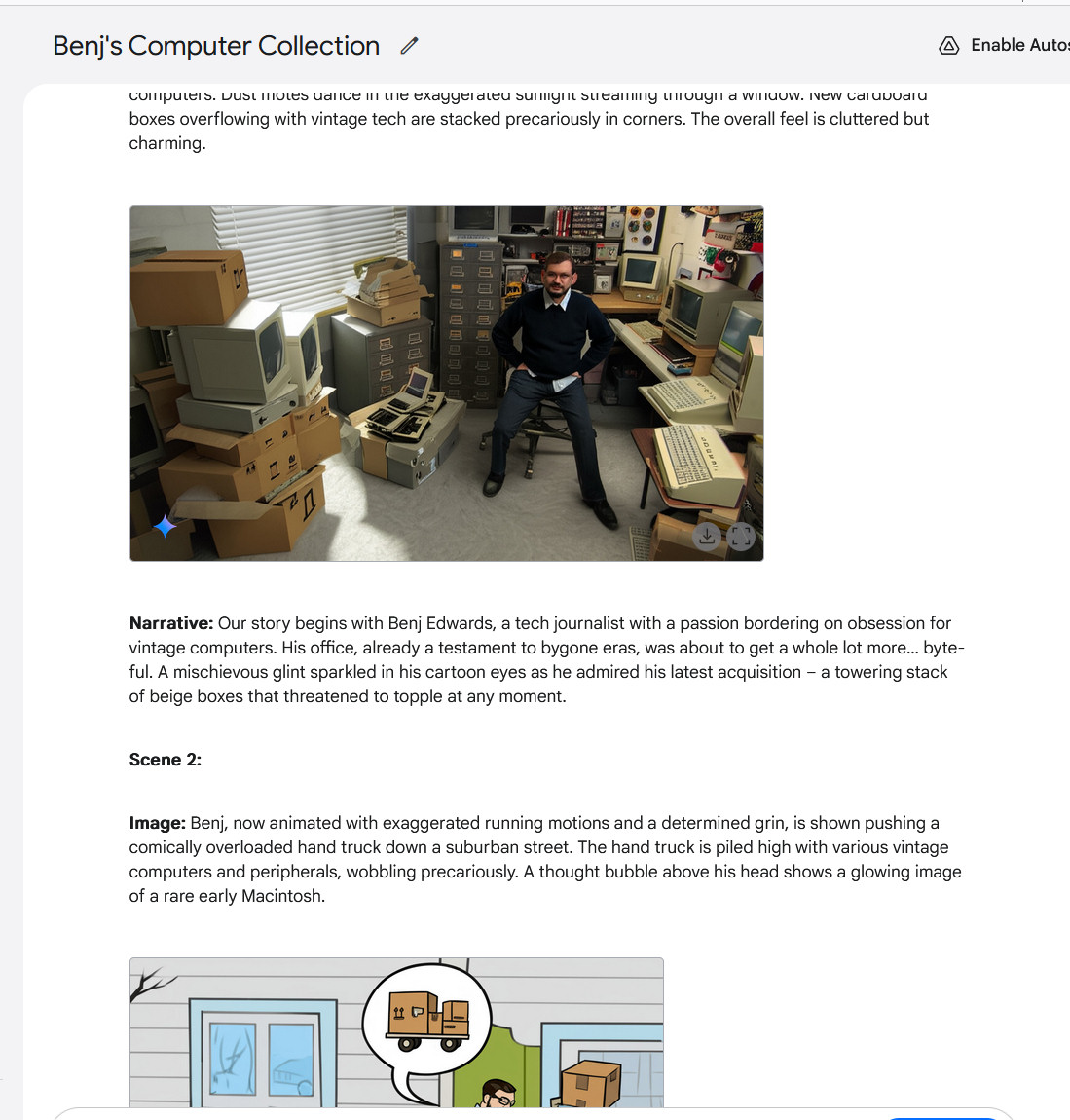
Making a multi-image story with Gemini 2.0 Flash, half 2. Uncover the selection angle of the distinctive image.
Google / Benj Edwards
Making a multi-image story with Gemini 2.0 Flash, half 2. Uncover the selection angle of the distinctive image.
Google / Benj Edwards
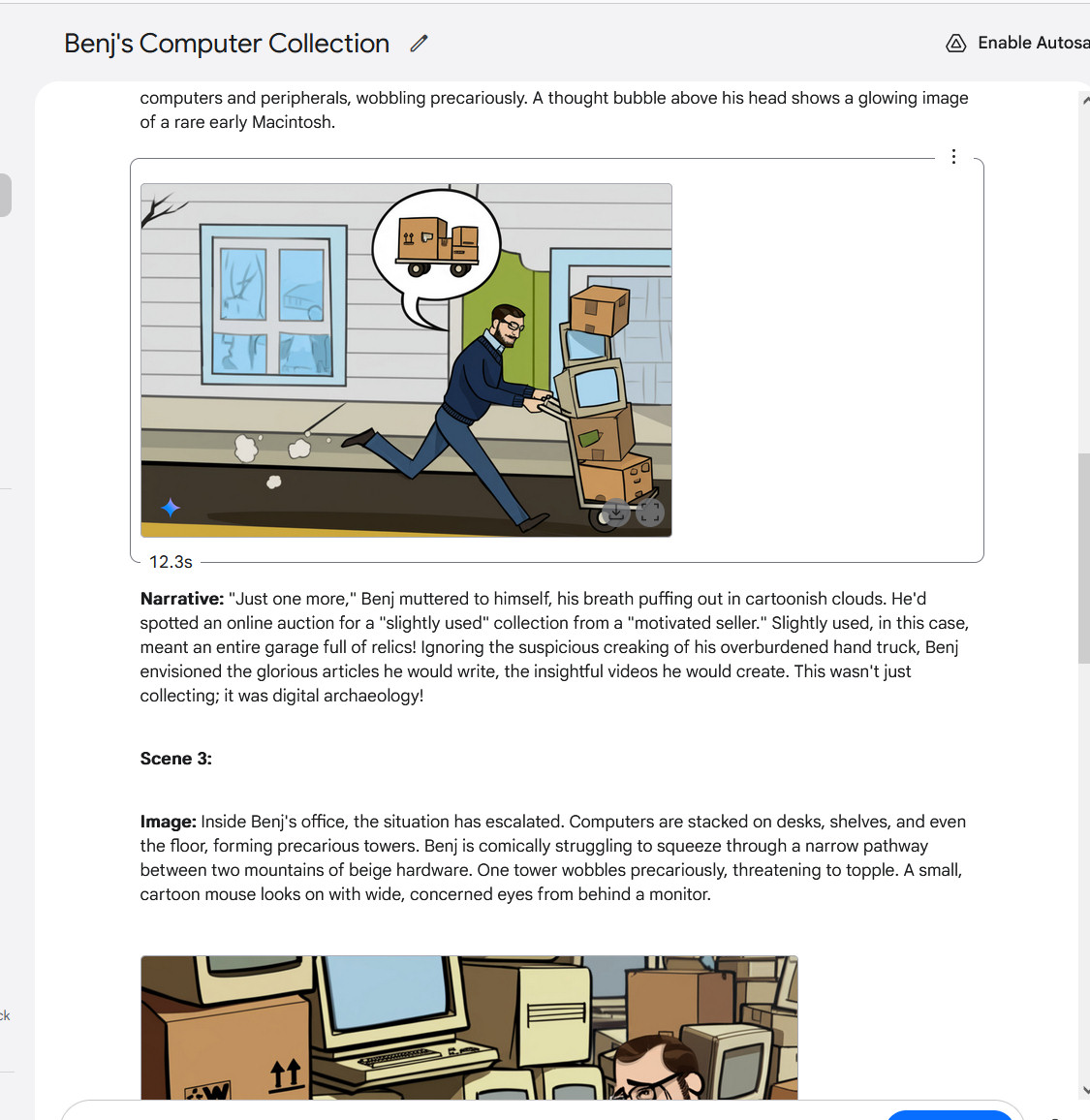
Making a multi-image story with Gemini 2.0 Flash, half 3.
Google / Benj Edwards
Making a multi-image story with Gemini 2.0 Flash, half 3.
Google / Benj Edwards
Making a multi-image story with Gemini 2.0 Flash, half 2. Uncover the selection angle of the distinctive image.
Google / Benj Edwards
Making a multi-image story with Gemini 2.0 Flash, half 3.
Google / Benj Edwards
Textual content material rendering represents one different potential vitality of the model. Google claims that interior benchmarks current Gemini 2.0 Flash performs larger than “principal aggressive fashions” when producing footage containing textual content material, making it doubtlessly applicable for creating content material materials with built-in textual content material. From our experience, the outcomes weren’t that thrilling, nevertheless they’ve been legible.
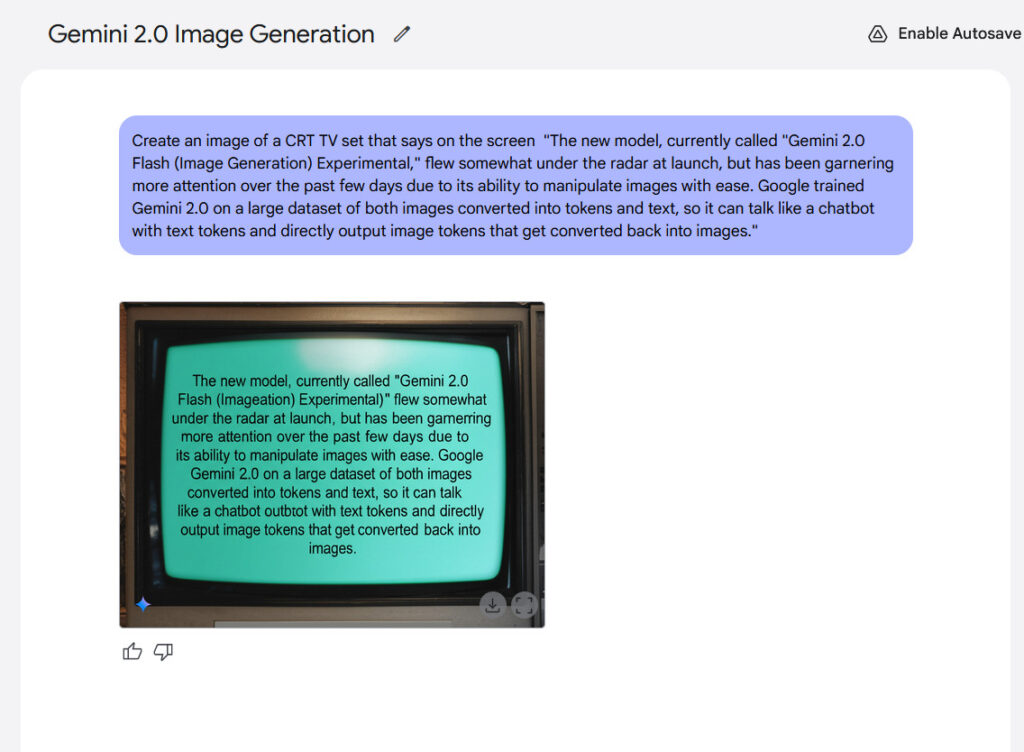
An occasion of in-image textual content material rendering generated with Gemini 2.0 Flash.
Credit score rating:
Google / Ars Technica
No matter Gemini 2.0 Flash’s shortcomings so far, the emergence of true multimodal image output seems to be like a notable second in AI historic previous as a consequence of what it suggests if the experience continues to boost. Ought to you consider a future, say 10 years from now, the place a sufficiently difficult AI model may generate any form of media in precise time—textual content material, footage, audio, video, 3D graphics, 3D-printed bodily objects, and interactive experiences—you principally have a holodecknevertheless with out the matter replication.
Coming once more to actuality, it’s nonetheless “early days” for multimodal image output, and Google acknowledges that. Recall that Flash 2.0 is supposed to be a smaller AI model that is faster and cheaper to run, so it hasn’t absorbed all of the breadth of the Net. All that information takes loads of space by the use of parameter rely, and additional parameters means additional compute. Instead, Google educated Gemini 2.0 Flash by feeding it a curated dataset that moreover doable included targeted synthetic info. In consequence, the model would not “know” all of the issues seen regarding the world, and Google itself says the teaching info is “broad and customary, not absolute or full.”
That’s solely a elaborate method of claiming that the image output top quality just isn’t good—however. Nonetheless there could also be a great deal of room for enchancment eventually to incorporate additional seen “information” as teaching methods advance and compute drops in worth. If the tactic turns into one thing like we now have seen with diffusion-based AI image generators like Safe Diffusion, Midjourney, and Flux, multimodal image output top quality may improve rapidly over a short timeframe. Put together for a very fluid media actuality.